Unicode - (1) 개념
모든 문자에 고윳값을 할당하는 테이블을 만드는 프로젝트가 유니코드 컨소시엄과 ISO 10646에 의해 시작됐다. 문제는 하나의 단체가 아니라 두 단체라는 거. 이거 다 편하자고 하는 일인데, 다른 두 개의 테이블이 만드는 것은 모든 사람이 원하지 않는 일이라는 것을 알고 같은 문자 셋을 만드는 걸 합의했다. 그냥 하나의 단체로 통합됐으면 하나 내가 모르는 사정에 의해 그것은 불가능한가 보다. 각자의 기준을 발표하는데, 항상 호환 가능하게 하고 있으니 이것만 해도 다행이다.
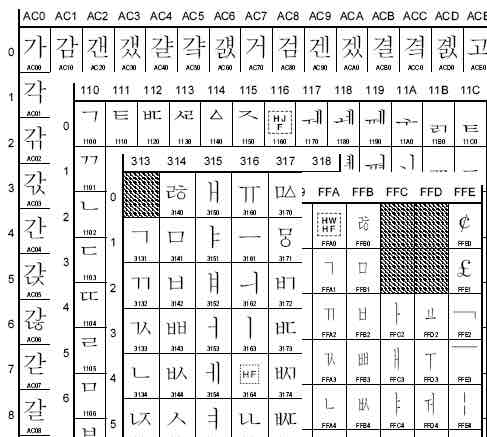
유니코드 컨소시엄의 유니코드와 ISO 10646의 UCS(Universal Character Set)은 문자에 고윳값을 할당하는 테이블일 뿐, 그 이상의 의미는 가지지 않는다. 여기서 문자에 할당되는 중복되지 않는 고유의 정수 값을 Code point라고 한다. UCS와 유니코드의 모든 문자들은 같은 위치를 가지며 같은 명칭을 사용한다. 참고로 Unicode 5.1에서 한글의 Code point는 다음과 같다. Hangul Syllables Range : AC00-D7AF, Hangul Jamo Range : 1100-11FF, Hangul Compatibility Jamo Range : 3130-318F, Halfwidth And Fullwidth Forms Range : FF00-FFEF
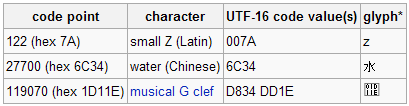
UCS-2, UTF-16은 둘 다 Code point를 2byte로 인코딩하지만 UTF-16은 가변 길이 문자 인코딩이고 UCS-2는 고정 길이 문자 인코딩인 게 다르다. 그러므로 UTF-16은 U+0000~U+FFFF의 BMP만 인코딩할 수 있는 UCS-2와 다르게 Unicode의 모든 code point를 인코딩할 수 있다. BMP를 벗어나는 code point는 문자가 할당되지 않은 surrogate code point로 알려진 U+D800~U+DFFF 의 조합으로 surrogate pair로 알려진 16bit 쌍으로 인코딩(32bit)한다. Unicode Technical Note #12 UTF-16 for Processing를 살펴보면 Unicode는 16bit로 인코딩하는데 최적화되어 있고 일반적인 문자는 BMP 범위를 벗어나지 않으니 BMP 범위를 벗어난 문자들만 살짝살짝 처리해주면서 사용하라고 한다.

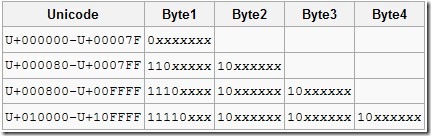
UTF-8은 US-ASCII 문자와 호환성을 가진 인코딩이다. 즉, U+0000~U+007F code point는 1byte로 인코딩되며 ASCII와 같은 코드 값을 가진다. UTF-16처럼 Unicode의 모든 code point를 인코딩할 수 있고 가변 길이 문자 인코딩이다. 인코딩된 코드값은 최소 1byte에서 최대 4byte이다. 기존 ASCII 문자와 호환성을 가지고, 영문자를 1byte로 표현할 수 있다는 장점이 있지만, 한글을 인코딩하면 3byte가 된다는 건 좀 불만이다. UTF-16에서 한글을 인코딩하면 2바이트이다. 1byte 스트림이기 때문에 BOM은 필요 없다.