Unicode - (4) 문자 개수 구하기, 변환(convert) code snippet
Unicode 문자 개수 구하기.
UTF-16 문자 개수 구하기.
int GetUtf16GlyphCount(const wstring& utf16) {
static const wchar_t HIGH_SURROGATE_MIN = L'\xD800';
static const wchar_t HIGH_SURROGATE_MAX = L'\xDBFF';
static const wchar_t LOW_SURROGATE_MIN = L'\xDC00';
static const wchar_t LOW_SURROGATE_MAX = L'\xDFFF';
bool bHighSurrogate = false;
int count = 0;
for(wstring::const_iterator iter = utf16.begin();
iter != utf16.end();
++iter) {
const wchar_t& ch = *iter;
if( HIGH_SURROGATE_MIN <= ch && ch <= HIGH_SURROGATE_MAX ) {
assert( !bHighSurrogate );
bHighSurrogate = true;
} else if( LOW_SURROGATE_MIN <= ch && ch <= LOW_SURROGATE_MAX ) {
assert( bHighSurrogate );
bHighSurrogate = false;
++count;
assert( count < numeric_limits<int>::max() );
} else {
assert( !bHighSurrogate );
++count;
}
}
return count;
}
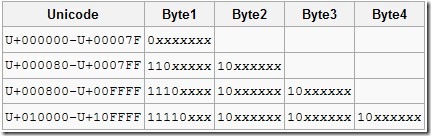
UTF-8 문자수 구하기.
#define assert_if(a, b) assert( !a || b )
int GetUtf8GlyphCount(const string& utf8) {
static const unsigned char ONE_BYTE_HEADER_MAX = '\x7F'; // 0xxxxxxx
static const unsigned char TWO_BYTE_HEADER_MAX = '\xDF'; // 110xxxxx
static const unsigned char THREE_BYTE_HEADER_MAX = '\xEF'; // 1110xxxx
static const unsigned char FOUR_BYTE_HEADER_MAX = '\xF7'; // 11110xxx
static const unsigned char TAIL_BYTE_MAX = '\xBF'; // 10xxxxxx
int tailByteCount = 0;
int count = 0;
for( string::const_iterator iter = utf8.begin();
iter != utf8.end();
++iter ) {
unsigned char ch = *iter;
assert_if( (ch <= ONE_BYTE_HEADER_MAX || ch > TAIL_BYTE_MAX), tailByteCount == 0 );
// 크기 오름차로 정렬해 비교한다.
// ONE_BYTE_HEADER_MAX 다음에 TAIL_BYTE_MAX를 끼어넣음
if( ch <= ONE_BYTE_HEADER_MAX ) ++count;
else if( ch <= TAIL_BYTE_MAX ) {
assert( tailByteCount != 0 );
--tailByteCount;
if( tailByteCount == 0 ) ++count;
}
else if( ch <= TWO_BYTE_HEADER_MAX ) tailByteCount = 1;
else if( ch <= THREE_BYTE_HEADER_MAX ) tailByteCount = 2;
else if( ch <= FOUR_BYTE_HEADER_MAX ) tailByteCount = 3;
else assert( ch <= FOUR_BYTE_HEADER_MAX );
}
assert( tailByteCount == 0 );
return count;
}
변환(convert)
MBCS -> UTF-16
wstring MbcsToUtf16(const string& mbcs) {
// 한글은 ANSI code page나 OEM code page 아무거나 써도 된다.
// Code Pages Supported by Windows - OEM Code Pages 참고
// http://www.microsoft.com/globaldev/reference/oem.mspx
// default로 설정된 코드 페이지를 사용하자.
int length = MultiByteToWideChar(
CP_ACP, 0,
mbcs.c_str(), static_cast<int>(mbcs.length()), 0, 0);
vector<wchar_t> buffer;
buffer.resize(length+1); // '\0'
MultiByteToWideChar(
CP_ACP,
0,
mbcs.c_str(),
static_cast<int>(mbcs.length()),
&buffer[0],
static_cast<int>(buffer.size()));
return &buffer[0];
}
UTF-16 -> UTF-8
string Utf16ToUtf8(const wstring& utf16) {
int length = WideCharToMultiByte(
CP_UTF8, 0,
utf16.c_str(), static_cast<int>(utf16.length()), NULL, 0, NULL, NULL);
vector<char> buffer;
buffer.resize(length+1); // '\0'
WideCharToMultiByte(
CP_UTF8, 0,
utf16.c_str(), static_cast<int>(utf16.length()),
&buffer[0], static_cast<int>(buffer.size()), NULL, NULL);
return &buffer[0];
}
UTF-8 <-> MBCS 변환 API는 제공하지 않는다. UTF-16을 거쳐야지 가능하다.
PS : character라는 단어를 사용하기가 애매했다. UTF-16, UTF-8 문자(character) 여러 개가 하나의 유니코드 문자(character)를 나타내는 경우가 있기 때문이다. 그래서 unicode character라고 써도 되나 glyph라는 단어를 선택했다. 네이밍은 끝까지 날 괴롭힐 것 같다.