#stl 정렬된 컨테이너의 검색 알고리즘 : upper_bound(), lower_bound(), equal_range(), binary_search()
O(logN)으로 수행되는 바이너리 검색(binary search)이다. 물론 바이너리 검색 알고리즘의 전제 조건인 정렬된 순서를 보장해야 하므로 원소들이 정렬된 컨테이너에서만 제대로 동작한다.
binary_search()
binary_search() 함수는 리턴값이 bool인 함수여서 원소가 컨테이너에 있는지 확인하는 용도로 사용한다. 확인만 하려는 경우에 반복자(iterator) 비교가 필요 없어서 간단하게 사용할 수 있다. 하지만 컨테이너에서 원소를 검색할 때 찾아낸 원소로 작업을 하는 게 대부분이라서 그닥 많이 사용할 것 같지는 않다.
// 컨테이너 정의
static const int arr[] = { 1, 2, 2, 2, 3, 3, 4, 5, 7, 7 };
typedef std::vector<int> IntVector;
IntVector v(arr, arr + sizeof(arr) / sizeof(arr[0]));
// 원소 출력
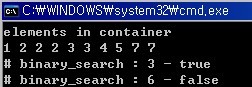
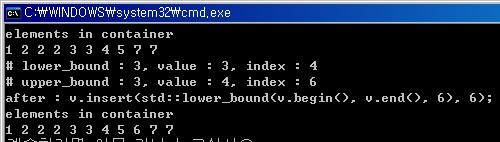
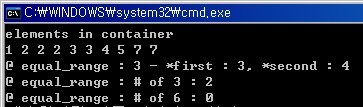
std::cout << "elements in container" << std::endl;
std::copy(v.begin(), v.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
// 검색
std::cout << "# binary_search : 3 - " <<
(std::binary_search(v.begin(), v.end(), 3) ? "true" : "false") << std::endl;
std::cout << "# binary_search : 6 - " <<
(std::binary_search(v.begin(), v.end(), 6) ? "true" : "false") << std::endl;
lower_bound(), upper_bound()
lower_bound()와 upper_bound()는 컨테이너의 정렬 상태를 깨지 않고 원소를 삽입할 수 있는 위치를 찾아주는 함수이다. 물론 바이너리 검색 알고리즘으로 검색한다.
// lower_bound : 3
IntVector::iterator upperIter = std::lower_bound(v.begin(), v.end(), 3);
std::cout << "# lower_bound : 3, value : " << *upperIter <<
", index : " << std::distance(v.begin(), upperIter) << std::endl;
// upper_bound : 3
IntVector::iterator lowerIter = std::upper_bound(v.begin(), v.end(), 3);
std::cout << "# upper_bound : 3, value : " << *lowerIter <<
", index : " << std::distance(v.begin(), lowerIter) << std::endl;
// lower_bound에 6 삽입
v.insert(std::lower_bound(v.begin(), v.end(), 6), 6);
std::cout <<
"after : v.insert(std::lower_bound(v.begin(), v.end(), 6), 6);" <<
std::endl;
PrintContainer(v);
헷갈리면 안 된다. 원소 위치를 찾아주는 게 아니라 해당 원소가 삽입돼도 정렬된 상태가 깨지지 않는 위치를 찾아준다. 만약 원소에 없는 원소를 find() 계열 함수로 찾으면 interator.end()를 리턴하지만 upper_bound()나 under_bound()는 삽입되어도 정렬된 상태를 유지할 수 있는 6의 위치를 반환한다.
equal_range()
equal_range()는 lower_bound(), upper_bound() 결과를 쌍으로 던져준다.
// equal_range : 3
typedef std::pair<IntVector::iterator, IntVector::iterator> IterPair;
IterPair iterPair = std::equal_range(v.begin(), v.end(), 3);
std::cout << "@ equal_range : 3 - *first : " << *iterPair.first <<
", *second : " << *iterPair.second << std::endl;
std::cout << "@ equal_range : # of 3 : " <<
std::distance(iterPair.first, iterPair.second) << std::endl;
// equal_range : 6
iterPair = std::equal_range(v.begin(), v.end(), 6);
std::cout << "@ equal_range : # of 6 : " <<
std::distance(iterPair.first, iterPair.second) << std::endl;
lower_bound(), upper_bound() 결과 두 개를 사용해야 하는 경우가 언제 있을까? 가장 먼저 생각나는 게 이 두 개가 있으면 원소 개수를 셀 수 있다. std::distance()를 사용해도 되고 그냥 반복자(iterator)를 빼도 된다. 이 두 반복자가 가리키는 범위는 [lower_bound_return, upper_bound_return) 인데, 산술적으로 빼기를 하면 이 범위의 개수를 셀 수 있다. [ , ] 범위면 +1을 해줘야 하고.
인자는 ForwardIterator
난 당연히 임의 접근 반복자(random access iterator)만 사용할 수 있는 줄 알았는데, 이건 좀 의외다. 순방향 반복자(Forward Iterator)를 지원하는 컨테이너면 사용할 수 있다. 즉, 리스트와 같이 원소 접근에 O(N)이 걸리는 컨테이너에도 사용할 수 있다.
// 컨테이너 정의
static const int arr[] = { 1, 2, 2, 2, 3, 3, 4, 5, 7, 7 };
typedef std::list<int> IntList;
IntList l(arr, arr + sizeof(arr) / sizeof(arr[0]));
// 컨테이너 출력
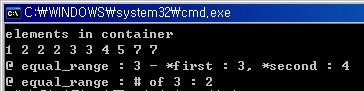
std::cout << "elements in container" << std::endl;
std::copy(l.begin(), l.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
// equal_range : 3
typedef std::pair<IntList::iterator, IntList::iterator> IterPair;
IterPair iterPair = std::equal_range(l.begin(), l.end(), 3);
std::cout << "@ equal_range : 3 - *first : " << *iterPair.first <<
", *second : " << *iterPair.second << std::endl;
std::cout << "@ equal_range : # of 3 : " <<
std::distance(iterPair.first, iterPair.second) << std::endl;
왜, 임의 접근 반복자로 제한하지 않았을까? 알고리즘은 O(logN)인데, 임의 접근을 지원하는 반복자가 아니라서 해당 원소로 이동하는데 O(N)이 걸린다. 원소 개수가 많으면 해당 원소로 이동하는데, 걸리는 시간이 검색 시간의 대부분을 잡아먹어 버린다. 그냥 선택지를 늘여주기 위해서인가? 아니면 정렬까지 했는데, 순차 검색보다는 낫다일까? 뭔가 이유가 있을 것 같기도 한데, 성능 문제는 뒤로 제껴놓고 생각하면 순방향 반복자를 지원하면 바이너리 서치가 가능하기 때문에 순방향 반복자를 패러매터로 받는 게 아닐까 싶다.
Principle of locality (Locality of reference)
빠른 검색을 위해서라면 O(logN)을 보장하는 Self-balancing binary search tree인 std::map을 사용하거나 이론상 O(1)인 hash table을 사용하면 된다. (TR1 부터는 정식으로 포함된다. STLport, 딩컴웨어에서 저마다 비공식 해시 테이블을 지원한다.) 하지만 최근에 접근된 데이터에 다시 접근하거나 그 데이터 주변에 접근하는 경향이 있다는 걸 뜻하는 Locality of reference를 생각해보면 연속된 메모리 공간을 가지는 vector가 캐시 적중률(cache hit rate)에서 유리하다.
결론
삽입과 삭제가 빈번한 컨테이너에서 빠른 검색이 필요하다면 뭐~ 볼 것도 없이 map이나 hash_table이다. 삽입, 삭제가 빈번하지 않다면 vector를 사용해 정렬하고 binary_search 사용을 고려해볼만 하다. 캐시 적중률 때문에 이론상 수치인 O(logN)보다 더 나은 퍼포먼스를 보인다. 게다가 연속된 메모리 공간을 보장하기 때문에 페이지 폴트(page fault)를 걱정하지 않아도 된다.
대충 이럴 때 사용하면 좋겠다고 감이 오지만 여기서 어디까지를 삽입, 삭제가 빈번하지 않다고 봐야 하는지가 문제이다. 이런 건 직접 써보고 퍼포먼스 테스트를 해서 결정하는 게 가장 확실하다. 이건 뭐~ 따로 얘기 안 해도 되는 뻔한 얘기고 대충의 가이드 라인을 잡아 본다면 매 프레임 삽입, 삭제가 기준이 될 것 같다. 매 프레임 삽입, 삭제가 이루어진다면 빈번하다고 봐야겠지.