
Unicode - (3) UTF-8 in Windows
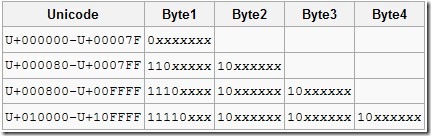
UTF-8 문자의 크기는 그림과 같이 1-byte에서 4-byte까지 가질 수 있다. 가장 큰 특징인 기존 US-ASCII와 호환성을 위해 이런 가변 길이 인코딩을 선택했는데, 덕분에 영어는 1-byte로 표현할 수 있지만 한글은 3-byte가 필요하다. 외국인이 쓰는 US-ASCII와 호환성도 있고 기존과 같이 1-byte로 표현할 수 있어서 외국인이 선호하는 인코딩으로 생각된다. Unicode 인코딩 중 UTF-8만 지원하는 라이브러리들이 많다.
#include <windows.h>
#include <string>
#include <iostream>
#include <clocale>
#include <vector>
using namespace std;
int main(int argc, wchar_t* argv[])
{
// US ASCII
wstring utf16Us(L"a~[]@#$");
vector<char> utf8Buffer;
// UTF-8 문자의 최대 크기는 4-byte, '\0' 저장할 공간 추가.
utf8Buffer.resize(utf16Us.size() * 4 + 1);
WideCharToMultiByte(CP_UTF8, 0,
utf16Us.c_str(), static_cast<int>(utf16Us.size()),
&utf8Buffer[0], static_cast<int>(utf8Buffer.size()), NULL, NULL);
string utf8Us(&utf8Buffer[0]);
// Korean
wstring utf16Kor(L"가나다라마바사");
// UTF-8 문자의 최대 크기는 4-byte, '\0' 저장할 공간 추가.
utf8Buffer.resize(utf16Kor.size() * 4 + 1);
WideCharToMultiByte(CP_UTF8, 0,
utf16Kor.c_str(), static_cast<int>(utf16Kor.size()),
&utf8Buffer[0], static_cast<int>(utf8Buffer.size()), NULL, NULL);
string utf8Kor(&utf8Buffer[0]);
wcout.imbue(locale("kor"));
wcout.clear();
wcout << L"US ASCII--------------------------------------------------" << endl;
wcout << utf16Us << L"\t\tUTF16 : " << utf16Us.size() * sizeof(wchar_t) << " bytes"
<< L"\tUTF8 : " << utf8Us.size() * sizeof(char) << " bytes" << endl;
wcout << L"KOREAN----------------------------------------------------" << endl;
wcout << utf16Kor << L"\tUTF16 : " << utf16Kor.size() * sizeof(wchar_t) << " bytes"
<< L"\tUTF8 : " << utf8Kor.size() * sizeof(char) << " bytes" << endl;
return 0;
}
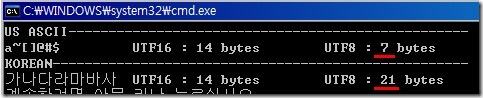
둘 다 7글자를 변환했다. UTF-16으로 인코딩 했을 때는 14-byte로 동일하나 UTF-8로 인코딩하면 US-ASCII는 7-byte가 되고 한글은 21-byte가 된다. 한글을 UTF-8로 인코딩하면 한 글자당 3-byte가 필요하기 때문에 한글이 많은 문서는 UTF-16으로 인코딩하는 게 유리하다.
Windows API는 UTF-8 문자를 지원하지 않는다. (물론 1-byte UTF-8 문자 제외)
UTF-8 문자의 저장 단위는 1-byte이기 때문에 char 데이터 타입에 저장한다. 또 다른 이유는 US-ASCII와의 호환성을 가지려면 같은 데이터 타입을 사용한다. Windows SDK에 있는 대부분의 API는 입력 문자열로 UTF-8 문자를 지원하지 않는다. US-ASCII, MBCS(MultiByte Character Set), UTF-16 만을 지원한다. 앞에 두 개를 지원하는 API는 뒤에 ’A’를 붙이고 UTF-16을 지원하는 API는 뒤에 ’W’를 붙인다. 물론, US-ASCII와의 호환성을 가지기 때문에 1-byte로 인코딩된 UTF-8 문자는 US-ASCII 문자열을 지원하는 API를 마음껏 사용할 수 있다. 만약 한글을 UTF-8 문자열로 가지고 있고 Windows API를 사용해야 한다면 MBCS나 UTF-16으로 인코딩한 후에 입력 문자열로 넣어줘야지 제대로 동작한다. Windows API는 UTF-16에 대한 지원이 좋아서 UTF-16 문자를 사용하는 게 편하다.
파일 입출력
파일 입출력을 하려면 BOM(Byte-Order Mark)을 알아야 한다. 원래 BOM은 little-endian과 big-endian은 구분하는 용도로 쓰이나 1-byte 단위 구성이어서 endian 구분이 상관없는 UTF-8에는 인코딩을 알려주는 목적으로 붙여준다. Windows에서는 Notepad를 비롯한 많은 윈도우 애플리케이션이 BOM을 붙여주고 있으니 권고 사항이라 생각하고 붙이도록 하자. UTF-8의 BOM은 `EF BB BF` 이다. BOM은 파일, 문자 스트림에서 첫 문자 위치에 적어주면 된다.
#include <windows.h>
#include <fstream>
#include <string>
#include <vector>
#include <cassert>
using namespace std;
int main(int argc, char* argv[])
{
wstring utf16(L"딱 하나의 문자열 인코딩만 있었으면 좋겠다!");
vector<char> utf8Buffer;
utf8Buffer.resize(utf16.size()*4+1);
WideCharToMultiByte(
CP_UTF8, 0,
utf16.c_str(), static_cast<int>( utf16.size() ),
&utf8Buffer[0], static_cast<int>( utf8Buffer.size() ), NULL, NULL);
string utf8(&utf8Buffer[0]);
static const string UTF_8_BOM("\xEF\xBB\xBF");
ofstream fileStream("utf_8.txt");
assert( fileStream );
if( fileStream )
{
fileStream << UTF_8_BOM << utf8 << endl;
}
return 0;
}
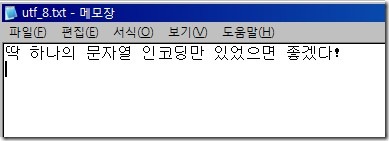
저장한 파일을 노트패드에서 열었다. BOM을 저장하지 않고 열어도 UTF-8로 인식을 하던데, 대부분의 윈도우 애플리케이션이 BOM을 사용하고 있으므로 파일에 문자열을 기록할 때, 안전하게 항상 BOM을 써주는 게 좋겠다.
#include <windows.h>
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <cassert>
#include <clocale>
using namespace std;
int main(int argc, char* argv[])
{
static const string UTF_8_BOM("\xEF\xBB\xBF");
static const int UTF_8_BOM_BYTE_COUNT = 3;
ifstream fileStream("utf_8.txt");
assert( fileStream );
// BOM
char buffer[UTF_8_BOM_BYTE_COUNT + 1]; // '\0' 공간을 더한다.
fileStream.get(buffer, UTF_8_BOM_BYTE_COUNT + 1);
string bom(buffer);
if( bom == UTF_8_BOM )
{
wcout.imbue(locale("kor"));
vector<wchar_t> utf16Buffer;
static const int INPUT_BUFFER_SIZE = 256;
char inputBuffer[INPUT_BUFFER_SIZE];
// 공백까지 읽기 위해 getline 함수를 사용.
while( fileStream.getline(inputBuffer, INPUT_BUFFER_SIZE).good() )
{
// UTF-16으로 변환에 필요한 wchar_t 개수를 얻어온다.
int size = MultiByteToWideChar(
CP_UTF8,
0,
inputBuffer,
INPUT_BUFFER_SIZE,
NULL,
0);
utf16Buffer.resize(size+1);
MultiByteToWideChar(
CP_UTF8,
0,
inputBuffer,
INPUT_BUFFER_SIZE,
&utf16Buffer[0],
size+1);
wstring utf16(&utf16Buffer[0]);
wcout << utf16 << endl;
}
}
return 0;
}
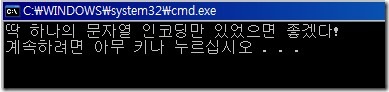
결론
US-ASCII와 호환성을 가져서 유니코드를 고려하지 않고 만든 API와의 호환성이 좋지만, Windows API들은 지원하지 않는 불편함이 있다. 암울한 건 Unicode 인코딩으로 UTF-8만 지원하는 라이브러리가 늘어가고 있다. 삐딱하게 생각해보면 유니코드는 지원해야겠고 자기들이 쓰는 영어가 2-byte로 인코딩 되는 건 못 마땅하고 해서 UTF-8만 지원하는 것 같다. 메인으로 UTF-16을 쓰고 UTF-8만 지원하는 라이브러리에 인코딩해서 문자열을 던져주는 방식으로 사용하는 게 좋을 것 같다.