Unicode - (2) UTF-16(wide character) in Windows
Windows에서 Unicode 인코딩은 UTF-16을 기본으로 사용하고 Unicode라고 부르기보다는 wide character라고 부른다. 그래서 Windows에서 wide character는 UTF-16 character라고 생각하면 된다. wide character 자료형인 wchar_t는 Windows에서는 2-byte이다. 여기서 자료형이 2 byte란 얘기지 UTF-16 문자가 다 2 byte란 얘기가 아님에 주의.
코드 상에서 문자,문자열 앞에 L 을 붙이면 wide character로 저장된다.
#include <iostream>
using namespace std;
int main(int argc, wchar_t* argv[])
{
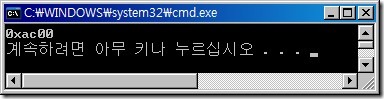
wchar_t temp = L'가';
// 모든 UTF-16 캐릭터가 2-byte라고 가정하고 코드를 짜는건 위험하다.
// BMP를 벗어나는 code point는 4-byte로 인코딩된다. 이건 테스트니깐 뭐~
wcout.setf( ios::showbase );
wcout.setf( ios::hex, ios::basefield );
wcout << static_cast<unsigned short>(temp) << endl;
return 0;
}
Standard output으로 출력은 Standard output으로 unicode 문자를 출력하기 (Win32 console application)를 참고하자.
Windows SDK는 유니코드 문자열을 지원하는 함수 프로토타입(function prototype)을 제공한다. 끝에 ’W’(wide)가 붙는 함수들이다.
#ifdef UNICODE
# define SetWindowText SetWindowTextW
#else
# define SetWindowText SetWindowTextA
#endif // !UNICODE
프로젝트 설정에 Unicode 사용을 체크하면 UNICODE 상수가 정의(define)되는데, Unicode 지원용 함수 프로토타입이 Generic Prototype으로 정의된다. 물론 문자열 종류에 따라서 SetWindowTextW, SetWindowTextA를 호출해도 된다. 이렇게 유니코드 사용 여부에 따라서 다른 함수 프로토타입을 정의하는 이유는 유니코드 사용 여부에 상관없이 코드가 잘 돌아가게 하기 위해서이다.
유니코드 문자열을 지원하는 CRT(C Run-Time library) 함수들은 wcs나 _wcs문자열을 함수 이름에 붙인다. 예를 들면 문자열을 비교하는 strcmp함수의 유니코드 버전은 wcscmp이다.
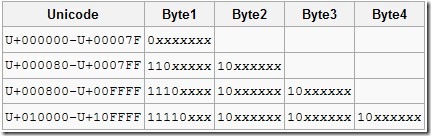
UTF-16 문자는 2-byte가 될 수도 있고 4-byte가 될 수도 있다. 2-byte 문자 두 개가 하나의 문자를 표현하는 것을 surrogate pair라고 하는데, Unicode에서 문자를 할당하지 않는 [U+D800,U+DFFF]의 값을 사용한다. 좀 더 자세히 살펴보면 surrogate pair를 이루는 문자 중 먼저 나오는 문자는 [U+D800,U+DBFF]의 값을 가지고 뒤에 나오는 문자는 [U+DC00,U+DFFF]의 값을 가진다. 그래서 문자 값이 [U+D800,U+DBFF]를 만족한다면 뒤에 문자 하나가 더 와서 하나의 문자(4-byte)를 이루게 된다. surrogates 문자6 의 출력 방법은 Surrogates and Supplementary Characters-MSDN에 설명되어 있다.
Arial Unicode MS는 Plane 0만 지원해서 surrogates 문자 정의가 안 되어 있다. Plane 1을 지원하는 Code2001 font를 찾아서 cmd.exe의 폰트로 설정이 안 되더라. 제길! WriteConsole로 출력해보니 폰트가 없어서 제대로 출력되지 않는다. 테스트는 안 해봤지만, 왠지 모르게 잘 출력해줄 것 같은데 말이지.